
University of Cambridge scientists say their proposal for a revolutionary new Internet architecture could make the Internet more “social” by eliminating the need to connect to servers and enabling all content to be shared more efficiently.
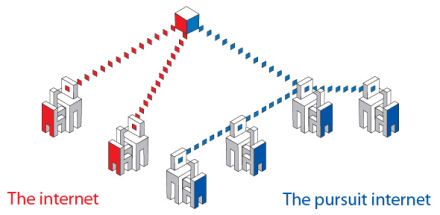
Dirk Trossen, the technical manager for Pursuit, explained that individual computers would be able to copy and republish content on receipt, providing other users with the option to access data, or fragments of data, from a wide range of locations rather than the source itself. Essentially, the model would enable all online content to be shared in a manner emulating the peer-to-peer (P2P) approach taken by some file-sharing sites, but on an unprecedented, Internet-wide scale.
This architecture, according to Trossen, would make the Internet faster, more efficient, and more capable of withstanding rapidly escalating levels of global user demand. Perhaps more importantly, it would theoretically make information delivery immune to server crashes.
“The current Internet architecture is based on the idea that one computer calls another, with packets of information moving between them, from end to end. As users, however, we aren’t interested in the storage location or connecting the endpoints. What we want is the stuff that lives there,” he explained. “Our system focuses on the way in which society itself uses the Internet to get hold of that content. It puts information first. One colleague asked me how, using this architecture, you would get to the server. The answer is: you don’t.”
As an example, Trossen said that if a user wants to watch their favorite TV show online, they search for that show using a search engine which retrieves a Uniform Resource Locator (URL) identifying which particular server stores the show. If, however, the user could correctly identify the content itself – in this case the show – then the location where the show is stored becomes less relevant. Technically, the show could be stored anywhere and everywhere. The Pursuit network would be able to map the desired content on to the possible locations at the time of the desired viewing.
Related:
Discuss this article in our forum
Researchers expose Google’s massive network expansion
Visible light data network under development
Txting tested for battlefield comms
Facebook Likes reveal surprisingly accurate intimate personal information
Source: University of Cambridge
Related posts:
 Laser sensor busts drunk drivers from outside car
Laser sensor busts drunk drivers from outside car
 Hipster or Goth? Software algorithm identifies your urban tribe
Hipster or Goth? Software algorithm identifies your urban tribe
 Decoded smartphone movements reveal transport mode
Decoded smartphone movements reveal transport mode
 Researchers demo human brain-to-brain interface
Researchers demo human brain-to-brain interface
 Kinect-like gesture recognition leveraged from standard WiFi signals
Kinect-like gesture recognition leveraged from standard WiFi signals
 Vacuum tube tech could save Moore’s Law
Vacuum tube tech could save Moore’s Law











Comments are closed.