
19 October 2007
Context And Computer Vision
By Rusty Rockets
 Compared to humans, computers are extremely clever when it comes to lightning-fast number crunching, or peering into the deepest, darkest corners of the universe. But when the contest comes down to plain old common sense, humans are streets ahead. The problem is quite simple: the computer's "brain" just isn't capable of assigning context to a scene filled with a myriad of seemingly unrelated objects. But as the quest to build a robot capable of mixing a dry martini (without poisoning you) and fetching your slippers (and not the cat) continues, a bunch of computer scientists believe they can create computers capable of seeing the world with a human perspective using a simple, but lesser-known, publicly available widget from Google.
Compared to humans, computers are extremely clever when it comes to lightning-fast number crunching, or peering into the deepest, darkest corners of the universe. But when the contest comes down to plain old common sense, humans are streets ahead. The problem is quite simple: the computer's "brain" just isn't capable of assigning context to a scene filled with a myriad of seemingly unrelated objects. But as the quest to build a robot capable of mixing a dry martini (without poisoning you) and fetching your slippers (and not the cat) continues, a bunch of computer scientists believe they can create computers capable of seeing the world with a human perspective using a simple, but lesser-known, publicly available widget from Google.
Computers capable of visually perceiving the world in the way that humans do has been a long-standing goal for computer scientists. But it's no easy task to imitate the human ability of identifying an object based on its shape, size, color, interaction with its environment, or the probability of the object being present in a particular environment (context). Humans process all of this information in a split second; so we know in an instant that the object next to the table is most likely a chair, and not a giraffe. We take this simple common sense for granted, but it is the kind of sense that is neither simple nor common to computers. In the last decade, however, object recognition and categorization research has enjoyed something of a resurgence among scientists and psychologists, which has led to the spawning of two promising avenues of enquiry: generative and discriminative algorithms.
Presenting his paper on computer visual recognition at this year's 11th International Conference on Computer Vision (ICCV), in Rio de Janeiro, Brazil this week, computer science professor Serge Belongie, from the University of California - San Diego, explains how these types of algorithm can characterize the organization of objects into real-world scenes.
A decade or so back, a smart cookie named Irving Biederman put forward a hypothesis comprised of five essential object recognition criteria, which are still being used today. The big five are:
- Interposition (objects interrupt their background)
- Support (objects tend to rest on surfaces)
- Probability (objects tend to be found in some contexts but not others)
- Position (given an object is probable in a scene, it often is found in some positions and not others)
- Familiar size (objects have a limited set of size relations with other objects)
But Belongie argues that while classes 1, 2, 4, and 5 have been represented well in subsequent object recognition models, poor old class 3 - the contextual interaction between object and scene - has been a tad neglected. And if Belongie is right, it looks as though the best may have been left until last. Subsequently, Belongie's team have identified two sources of semantic context (or discriminatory) information that can be used to constrain automated object categorization: the co-occurrence of object labels in training sets, and generic context information retrieved from Google Sets.
The first of these methods can get a little complicated, as it leads into the realms of artificial intelligence theory. The simplest way to conceptualize the co-occurrence of objects in training sets is to think of a knowledge database being trained to accurately identify X among a myriad of other data. A trained intelligence device should be able to digest a number of variables and provide an answer (output) based on those variables. But it's a process that isn't, yet, as deterministic as a computer calculating the sum of 1 + 1, and is instead based more on probability.
One example that many people may have come across is the language recognition software that often comes bundled with a computer. In this instance you are training the computer to associate your voice with the keyboard, and other commands used to control your computer. But it takes some time before the system will work satisfactorily (and even then it's ongoing), because you don't always say words with the same tone, pronunciation, or intonation, or maybe there's some background noise, or you have a cold. This is similar to how object recognition software takes time to be trained using co-occurrence of different object labels in identifying one particular object in any number of different scenes.

Idealized Context Based Object Categorization System. An original image is perfectly segmented into objects; each object is categorized; and objects' labels are refined with respect to semantic context in the image.
The team explains that by segmenting images sections and labeling them accordingly, a much more accurate image constraint system would be possible. "Using segment representations incorporates spatial groupings between image patches and provides an implicit shape description," the authors write. However, Belongie explains that currently most images and image databases don't have labeled data or training sets that would allow for this kind of contextuality. To this end, Belongie and his colleagues want to create contextual constraints in regard to images derived from a common knowledge base sourced from the Internet. "In particular, we wish to generate contextual constraints among object categories using Google Sets," says Belongie.
Google Labs' tool, Google Sets, a contextual semantic generator, can add an extra dimension to automated object identifiers in the form of "external semantic context." So, if you were to type Labrador, Bull Terrier, or Poodle into Google Sets, then it would return the words German Shepherd, dogs, or Kelpie. "We think our paper is the first to bring external semantic context to the problem of object recognition," says Belongie. Current object identifiers observing a tennis match might identify a round, yellow object being hit by a paddle-shaped thingy as a lemon, which just wouldn't do at Wimbledon. Comparatively, segmentation of images into stable image sets (pre-processing), coupled with the use of Google Sets (post-processing) would place the object into context with other objects - such as the tennis racket and the player - and identify, probabilistically, the yellow object as a tennis ball. "In some ways, Google Sets is a proxy for common sense. In our paper, we show that you can use this common sense to provide contextual information that improves the accuracy of automated image labeling systems," said Belongie.
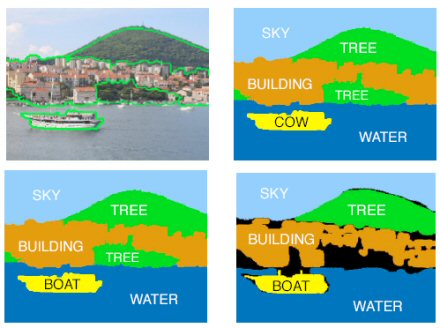
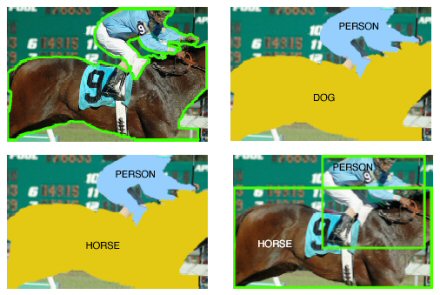
In both MSRC (top) and PASCAL (bottom) we can see how contextual constraints result in better image labeling. (a) Original Segmented Image. (b) Categorization without contextual constraints. (c) Categorization with co-occurence contextual constraints derived from the training data. (d) Ground Truth
The mechanics behind the image labeling system can be boiled down to a fairly straightforward three-step process. The first step involves breaking down a complete image into smaller segmented image regions, which are then ranked into probable labels for each image segment. The final process involves comparing possible combinations of the labeled images to further verify the image contextually. "We evaluated the performance of our approach on two challenging datasets: MSRC and PASCAL. For both, the categorization results improved considerably with inclusion of context," writes Belongie. Further accuracy was attained by generating and analyzing more than just one image segmentation, and creating a shortlist of stable image candidates.
But using Google Sets in its current form has constrained the project somewhat, and the team found that "using ground truth [which compares automated object identification with what is actually being identified] semantic context constraints were much higher than those of Google Sets due to the sparsity in the contextual relations provided by Google Sets," explain the authors. But Belongie believes this situation will improve with time. "In considering datasets with many more categories, we believe that context relations provided by Google Sets will be much denser and the need for strongly labeled training data will be reduced." In their current work, the team are exploring ways in which the generation of semantic context relations between object categories can be free of training data altogether. "Semantic object hierarchies exist on the web, e.g., from Amazon.com, and will be utilized in this research", conclude the team.
Automated software capable of identifying specific objects within a scene of otherwise confusing data will likely become the foundation of future Internet search engines. But other devices in the future would also benefit. Security systems would be a lot smarter and harder to fool, and anything from survey and film equipment could be considered intelligent. Just imagine a video camera that can identify and track an object using its own discretion. Which begs the question: would the likes of Roddick or Federer yell at an automated umpire?
View the paper "Objects In Context": http://www.cs.ucsd.edu/~sjb/iccv2007a.pdf
Related:
A Portrait Of The Artist As A Tin Man
Bringing Up BabyBot
Artificial Eye Borrows From Nature
Artificial Intelligence In The Garden Shed
Eye Of The Beholder Redux